With the development of artificial intelligence and IoT technology, we are seeing the proliferation of smart devices. Around us, there are new smart equipment categories such as smart speakers, early education robots, and sweeping robots. At the same time, in the fields of smart industry, smart city and smart retail, the pace of intelligence is also moving forward. We have seen that under such a development trend, the traditional MCU chips are undergoing profound changes and are developing in the direction of intelligence.
Intelligent Internet of Things and MCU intelligence
The rise of this wave of artificial intelligence originated in big data and deep learning. With the development of the Internet, human society has generated a large amount of data, and big data and deep neural network algorithms can train some highly accurate machine learning models, which can stimulate new applications such as face recognition, automatic driving, and speech recognition. In the artificial intelligence based on big data, the terminal node is responsible for collecting data and handing it over to the cloud. The cloud server repeatedly iteratively trains high-precision models and finally deploys these models into the application. It should be said that the tasks of data collection and model training are currently recognized in the terminal and the cloud respectively, but the specific deployment of the machine learning model is different in different applications.
Some applications (such as camera content analysis) are deployed in the cloud, that is, the terminal completely returns the original data to the cloud, and the cloud performs the deep learning model reasoning on the data, and then sends the result back to the terminal, and the terminal according to the cloud. As a result, the corresponding operation is performed; in an application such as automatic driving, the model must be deployed at the terminal, that is, the terminal performs local reasoning of the deep learning model after collecting the data, and performs corresponding actions according to the result. In a scenario such as the smart industry that needs to perform deep learning model reasoning in the terminal, the MCU originally used to perform the relevant action must be able to support such deep learning inference calculation, which is the intelligentization of the MCU.
In general, the reasons why machine learning models must be deployed at the end of the terminal include transmission bandwidth, latency, and security. Considering the transmission bandwidth, the nodes in the Internet of Things are currently distributed in various scenarios. If the original data is to be directly transmitted to the cloud, the bandwidth overhead is very large, and the energy cost of wireless transmission is not small. If you deploy machine learning reasoning on the terminal, you can save bandwidth overhead, and only need to selectively transfer some important data to the cloud without transmitting all the original data.
Reaction delay is also an important reason to deploy deep learning at the terminal. At present, the data transfer time to the cloud is usually in the order of hundreds of milliseconds, which is not satisfactory for applications such as industrial robots with high requirements for delay. Even in a 5G low-latency network, the reliability of a wireless network is difficult to meet the demand for high-reliability applications such as smart industries. Occasionally high latency or even data loss can cause problems in machines that require immediate response. Therefore, it tends to choose to put the calculation of deep learning reasoning locally.
Finally, data security is also a consideration. For some sensitive applications, transmitting data to the cloud server over the network means that there is a risk of data being compromised—if the hacker controls the entire factory by cracking the data of the smart factory and the cloud server. It will bring huge losses to the factory – and it would be safer to put these calculations locally.
According to the above scenario, we believe that the MCU that needs to perform local machine learning inference calculation mainly runs in the following scenarios:
Intelligent production requires rapid response and attention to data security, such as identifying machine faults based on sound;
Small robots, no one will hope that once the robot is disconnected from the network, it will not work, such as drones, sweeping robots, etc.;
Smart home appliances, such as smart air conditioners, are intelligently supplied according to the location of the person;
Intelligent wearable devices, such as giving corresponding prompts according to physiological signals of the human body.
With the above-mentioned requirements for performing machine learning inference calculations in terminal deployments, some MCUs that were originally only responsible for executing basic programs must also have the ability to run machine learning inference calculations. The challenge for MCUs lies in computing power, because in this wave of artificial intelligence, the amount of computation required to train a good model is usually hundreds of thousands of calculations to hundreds of millions of calculations, if you need to perform these operations in real time. Then the computing power required by the MCU will be several orders of magnitude stronger than the original MCU.
In addition, smart MCUs also have high requirements for power consumption and real-time performance, which requires MCU design to change accordingly. At present, the MCU is in the process of upgrading from 8 bits to 32 bits. We expect that based on the 32-bit MCU, intelligence will become the evolution direction of the next MCU.

Intelligent Technology Path 1: Integrating Accelerator IP
At present, in the field of MCU, ARM has occupied the position of leader, and its IP has occupied a large market share. For the rise of intelligent MCU, ARM naturally will not stand by, but play a role as a promoter to help the MCU achieve intelligence.
ARM's Cortex series architecture dominates the 32-bit MCU, so ARM's approach to advancing intelligent MCUs needs to take into account its Cortex architecture, and it is not possible to push its own life in order to push the results of intelligent MCUs. Therefore, ARM chose to equip the Cortex core with a separate accelerator IP, which is called when the machine learning related algorithm needs to be executed, and Cortex is used as a traditional operation.
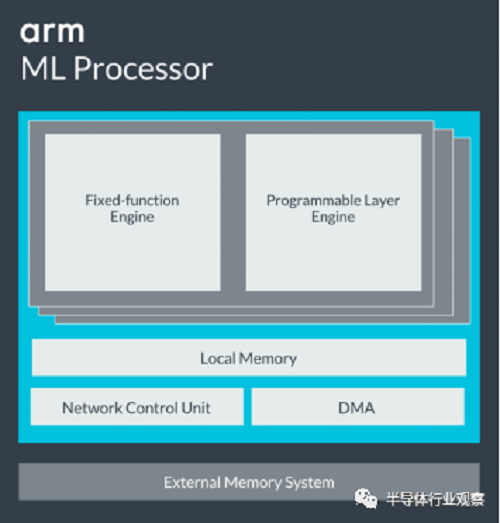
ARM's machine learning accelerator series, Project Trillium, includes hardware IP such as machine learning processor (ML Processor) and object detection processor. It also includes algorithms for optimizing execution on these accelerators and Cortex cores and Mali GPUs. Software stack ARM NN. Take the ARM ML Processor as an example (as shown below), its architecture includes an acceleration engine Fixed-function Engine for accelerating dedicated functions, a programmable layer engine for speeding up the neural network, Programmable Layer Engine, on-chip memory for controlling accelerator execution. Network control unit and DMA for accessing off-chip memory.
The ARM ML Processor is a typical accelerator architecture. It has its own instruction set and can only perform computational acceleration related to machine learning and cannot run other programs. Therefore, it must work with the Cortex core. The ARM ML Processor can realize the power of 4.6TOPS, and the energy efficiency ratio can reach 3TOPS/W. The performance is excellent. For the occasions with low computing power, the power consumption can be reduced to reduce the power consumption to meet the needs of the MCU.
In addition to ARM, other MCU giants are also deploying AI accelerators, of which STMicroelectronics is a technological leader. In the past year, STMicroelectronics released its dedicated convolutional neural network accelerator for ultra-low-power MCUs, code-named Orlando Project, which achieves an ultra-high energy efficiency ratio of 2.9TOPS/W on 28nm FD-SOI. Further demand for market demand will be converted to commercialization.
It should be said that the current intelligent MCU based on the dedicated machine learning accelerator IP is still in a ready stage. As the name implies, the dedicated machine learning accelerator achieves a high energy efficiency ratio through a dedicated design. However, this limits the scope of application and only speeds up part of the machine learning algorithm, not the versatility.
At present, the most important object of acceleration for machine learning accelerators is neural network algorithms, especially convolutional neural networks. Technically speaking, the convolutional neural network has high parallelism in the execution process, and there is an accelerating space. An accelerator can increase the execution speed and energy efficiency ratio of the neural network by several orders of magnitude compared with the conventional processor. From the perspective of the development of artificial intelligence, the most successful application of this wave of artificial intelligence is also based on the machine vision application of convolutional neural networks, so it is logical to focus on the acceleration of convolutional neural networks.
However, for MCUs, focusing on convolutional neural network acceleration is not necessarily a choice for Zui optimization. First of all, the application of the MCU market is fragmented, and a dedicated accelerator is difficult to cover multiple applications. Therefore, it is necessary for a semiconductor manufacturer accustomed to designing a standardized MCU and taking over many markets to use a dedicated accelerator. Carefully consider the choice. In other words, in many applications, intelligent MCUs can efficiently execute non-convolution neural network-based machine learning algorithms (such as SVM, decision trees, etc.), so these applications cannot be covered by a dedicated convolutional neural network accelerator. And you need to design another set of accelerators. Of course, this is not a bad thing for the IP vendor ARM, because ARM can quickly increase the number of IP classes in its machine learning accelerator and profit from it, but it is a headache for semiconductor companies.
In addition, the most successful application of convolutional neural networks is machine vision. However, there are many other applications besides machine vision in MCU applications. It can even be said that machine vision in intelligent MCU applications is not a big market, which limits the market. Only the market for dedicated accelerator IP for convolutional neural networks can be processed.
Intelligent Path 2: Improved Processor Architecture
According to the above discussion, ARM has occupied the MCU market because it used the Cortex core. Therefore, it is inevitable that it will retain the Cortex architecture and push the dedicated accelerator IP that can be used with the Cortex core. However, intelligent MCUs based on dedicated machine learning accelerator IP will encounter narrow application coverage in fragmented applications, which is why there is a second MCU intelligent technology path - improved processor architecture.
Improved processor architecture means designing a low-power, high-powered general-purpose processor directly, so that it can cover almost all MCU applications, thus avoiding the versatility of dedicated accelerators. Of course, in the processor design, it is often necessary to completely redesign from the instruction set, so it requires a lot of investment.
According to the tradition of the semiconductor industry, designing a new set of self-contained instructions from scratch is often difficult and unpleasant, because the design, verification, scalability considerations, etc. of the instruction set are often not completed by a team, but require a large number of People work hard for a long time. However, with the increasing acceptance of the RISC-V open source instruction set, the use of the RISC-V instruction set to implement new processor architectures can significantly reduce the cost and risk of instruction set and architecture development. The RISC-V instruction set has been certified by the open source community and has proven to be very reliable. It is not necessary to build wheels from scratch, but only needs to focus on the parts that need improvement. Therefore, it is a good idea to make a new processor architecture at this point in time. Time.
The representative company that uses the new architecture as a smart MCU is the French startup Greenwaves Technologies. Greenwaves uses the RISC-V-based instruction set, and also introduces the concept of multi-core in the MCU. It accelerates parallel computing in artificial intelligence algorithms by means of multiple data streams (SIMD). It can be described as MCU architecture. An innovation on the top.
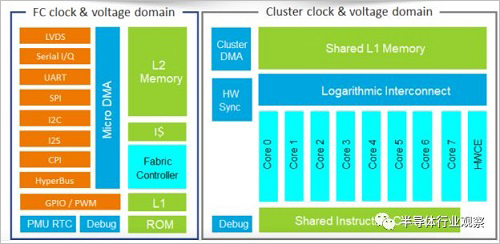
Currently, Greenwaves' first product, GAP8, is already in the production stage. According to the data, GAP8 has 8 cores and can realize 8GOPS computing power with tens of milliwatts of power consumption. This computing power can meet the needs of many intelligent MCUs. More critically, because GAP8 uses a multi-core general-purpose processor instead of a dedicated accelerator to accelerate artificial intelligence algorithms, it can be very versatile and can cover a variety of algorithms and applications. In the application of fragmented MCU market, this is undoubtedly a big advantage. Due to the use of general-purpose processors, the energy efficiency of GAP8 is weaker in specific areas than ARM-specific accelerators, but the versatility of GAP8 is beyond the reach of ARM's dedicated accelerators.
It's also worth noting that the new processor architecture and dedicated accelerators are not incompatible, and it is possible to integrate a dedicated accelerator while using the new processor architecture to use a dedicated accelerator to accelerate specific applications while using a new, generic architecture. To handle efficient processing of other applications. The choice of dedicated and versatile here is largely dependent on market demand and potential business returns.
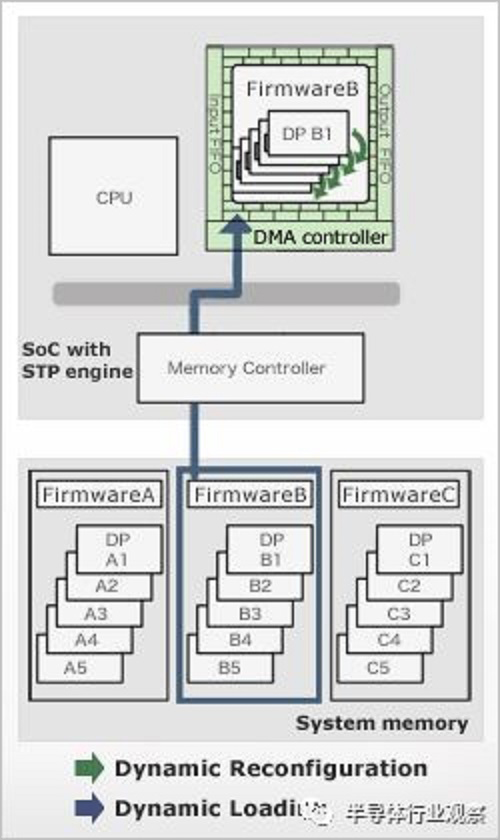
In addition to Greenwaves, Renesas has introduced a similar new processor architecture. A little different from Greenwaves, Renesas is not a new general-purpose processor architecture, but a configurable coprocessor that can be programmed in a high-level language (such as C/C++). Different application scenarios can be configured with different architectures to balance versatility and specificity. Renesas called the architecture a Dynamic Reconfigurable Processor (DRP), which has been previously validated in Renesas' video processors, and now Renesas is ready to move the architecture to the MCU. And will officially release the first generation of integrated DRP MCUs in October this year.
Conclusion
The combination of artificial intelligence and the Internet of Things advances the concept of intelligent MCUs. We expect to see the popularity of smart MCUs in the next few years, and the choice between the two technology paths of smart MCUs will not only affect the MCU market, but will also have a profound impact on the semiconductor ecosystem – if dedicated accelerator IP If you win, ARM will continue to be the leader of smart MCUs, and if the new architecture wins, ARM will face strong challenges.
Silicone Watch Band
About silicone watch bands:
With the development of the society,people demand more and more high standard of live. In the same time,we can find out from their decorations, they are also beginning to pay attention to product safety and environmental protection, for example silicone watch bands. The silicone watch band made of food grade silicone,It is very safe and good for the environment. Its texture is soft and durable,it can be clean easily and its dirty resistance is very good! many athletes and the office workers like it,even the old or young!
The following silicone watch bands photos for your reference:

Waterproof Watch Strap,Silicone Rubber Strap,Casio Watch Bands,Sport Strap Watch Band,Apple Watch Bands
Dongguan OK Silicone Gift Co., Ltd. , https://www.dgsiliconepettags.com